[KMOOC 강화학습] Week 07-2 Policy Iteration
해당 강의는 K-MOOC의 “강화학습의 수학적 기초와 알고리즘 이해” 수업을 수강하며 기록한 내용입니다. 강의는 링크에서 확인하실 수 있습니다.
Policy Iteration
정책 방법 알고리즘이라고 불리며 infinite horizon MDP를 푸는 방법이다. 이 방법은 임의의 정책을 바탕으로 정책 자체를 업데이트 한다.
- 계산의 용이를 위해 임의의 정책을 초기화 한다. 이에 대한 증명도 밝혀져 있다.
- 이 반복은 모든 상태에 대한 각각의 정책이 변화하지 않을 때까지
Iteration
아래의 단계들을 반복하며 정책을 업데이트 할 때 가치함수 값이 항상 커지는 것이 보장되어 있게 된다. 그 과정을 통해 최적 정책을 찾게 되는 것이다!
정책 평가 단계
정책이 주어졌을 때 모든 상태에 대해 가치함수를 찾는 과정으로 누적 보상합의 기댓값으로 계산하고, 재귀식을 활용하게 된다.
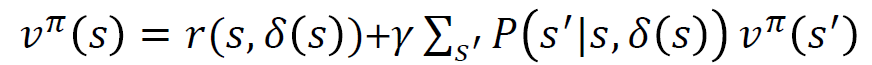
이 식은 모든 상태에 대한 가치를 계산하는 행렬 방정식은 다음과 같다.
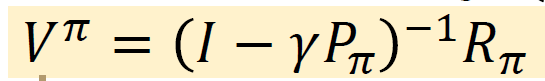
정책 개선 단계
정책을 업데이트 할 것인데 Bellman Optimality Equation에서 우변을 풀게 되고, 이 때 모든 상태에 대한 가치함수 값은 앞서 정책 평가 단계의 결과 값을 사용하기로 한다.
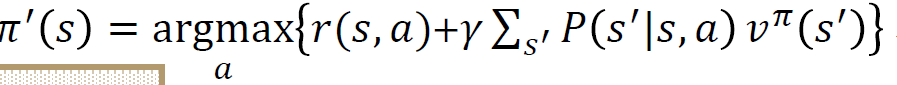
이 때 우변의 2번째 항의 값을 앞서 구한 정책 평가 단계의 값을 사용하게 된다.
이 단계에서는 함수의 값을 최대화하는 행동을 찾는 것이다!
예시
자동차
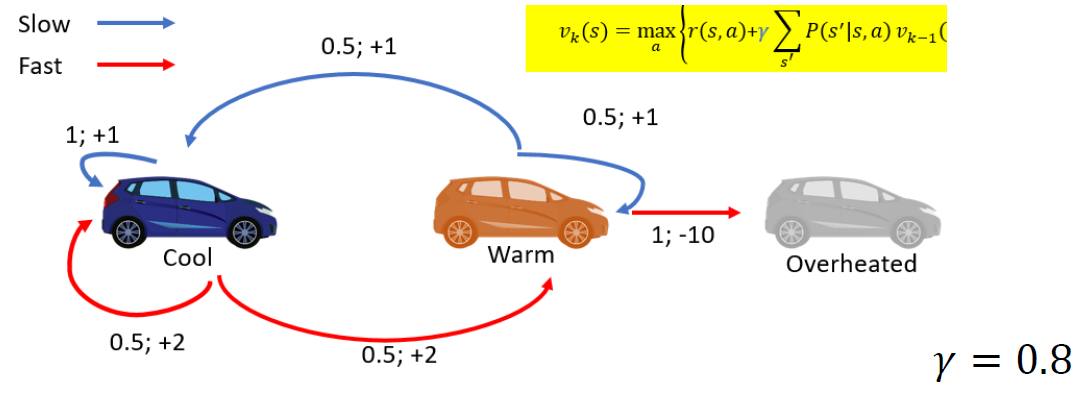
가능한 모든 정책을 나열하고 최대값을 찾아도 되니 다음과 같다.
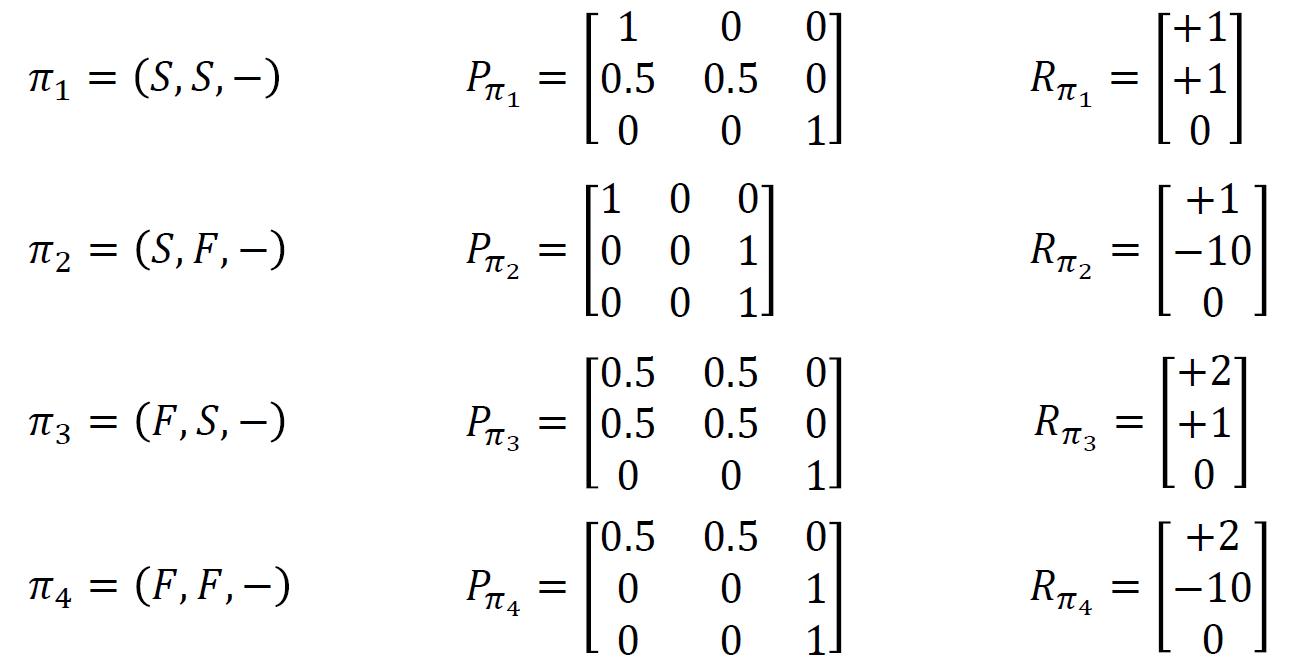
여기서 말하고자 하는 것은 Cool, warm, Overheated 상태에 대해 행동들을 열거해놓은 것이고 그 때의 전이행렬 P를 구한 것이고, 열거한 각 행동들에 대해 보상도 맞춰서 기록한 것이다.
그런데 이렇게 다 열거할 수 없다면…?
Policy Iteration
Iter 1
- 임의의 정책을 초기화 한다.
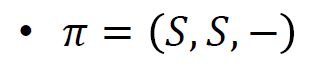
- 정책평가한다.
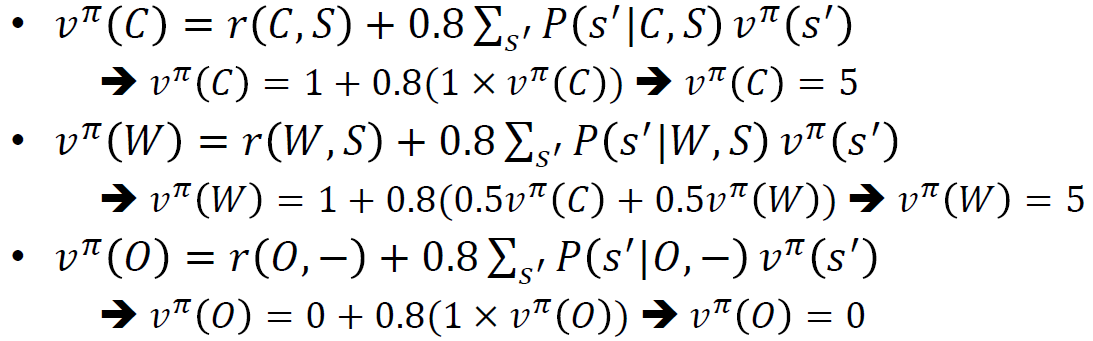
이 경우에는 순서대로 풀게 되면 모든 가치함수에 대한 값을 구할 수 있게 된다.
- 정책 개선한다.
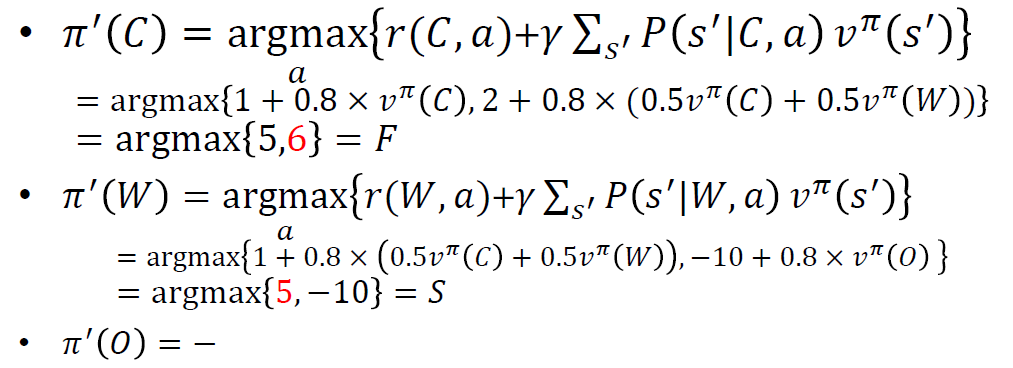
여기서 중요한 것은 그런 최대값이 되도록하는 행동을 찾아야 하는 것이다.
Iter 2
- 정책평가한다.
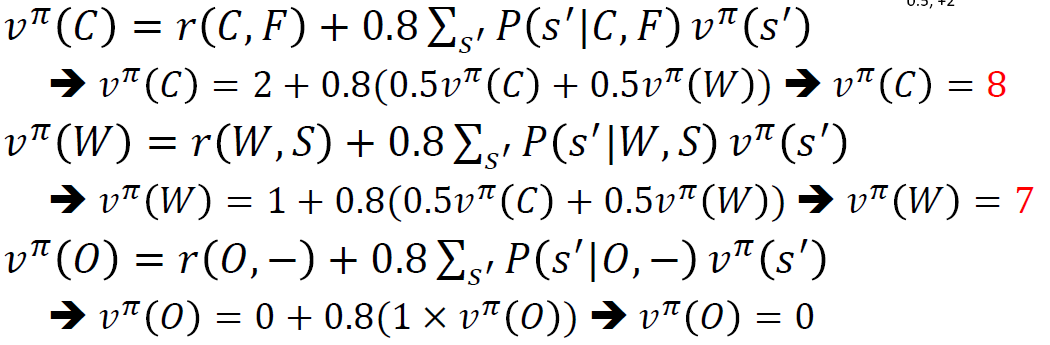
이 경우에는 연립방정식이 되어서 이를 풀어주면 된다.
- 정책 개선한다.
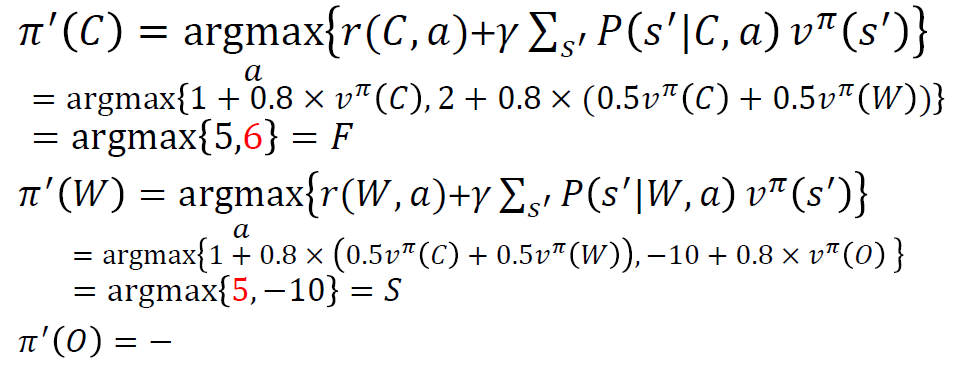
이 과정에서 정책 개선이 없다면 정책 차이가 없기에 동일한 결과를 받을 것이라 멈추면 된다.
Jack’s car rental
구성요소
- 상태 s: 재고로 [(지점1 재고, 지점2 재고)]
- 행동 a: 지점 1에서 지점 2로 교환 [-5,-4,…,3,4,5]
결과
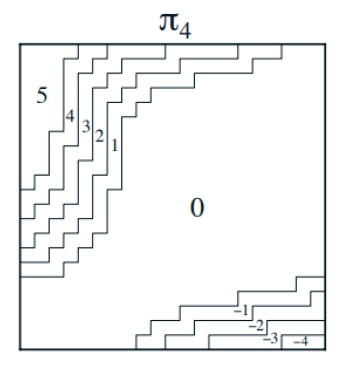
요약
- Infinite horizon MDP에서 해결책으로 value iteration과 policy iteration이 있었고
- policy iteration횟수가 적었지만
- 한 iteration에서 연산량은 policy가 더 많았는데
- 이는 정책을 평가하고 개선하는 2개의 과정이 있었기 때문이다.
댓글남기기