[KMOOC 강화학습] Week 09-1 Model-free Reinforcement Learning
해당 강의는 K-MOOC의 “강화학습의 수학적 기초와 알고리즘 이해” 수업을 수강하며 기록한 내용입니다. 강의는 링크에서 확인하실 수 있습니다.
강화학습이란
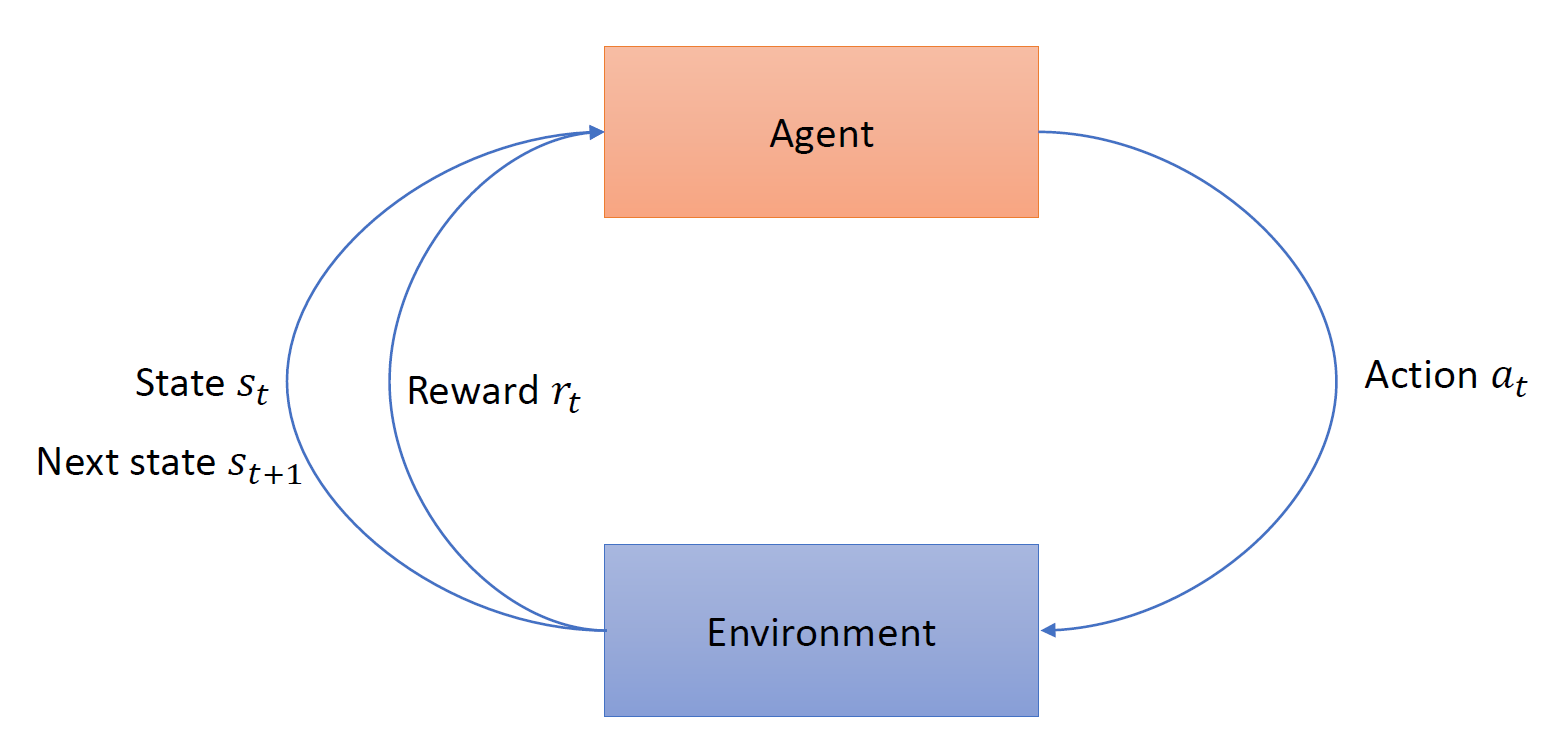
상태에 따라 행동을 취하고 보상을 받고 다시 상태가 전이되는 구조가 된다. 그래서 agent는 어떤 환경에서 어떤 행동이 보상을 최대화하는지 학습하는 것이다!
infinite horizon MDP
구성요소
- 상태공간
- 행동공간: 상태에 따라 취할 수 있는 행동들이 달라질 수 있다.
- 상태 전이 확률: 어떤 상태에 어떤 액션을 취하면 다음 상태에 대한 예측 정보를 가진 것
- 보상
- 감가율: 누적보상이 수렴하기 위해서 사용하는 값으로 미래 가치를 현재 가치로 환산해준다.
목표
최적 policy를 찾자!
finite MDP는 상태에 따라 행동이 달라지기 때문에 의사결정 규칙들의 집합이 되기도 한다.
다만 infinite horizon MDP는 stationary가정에 따라 의사결정 규칙이 결국 정책이 되는 상황이다. 즉 상태를 행동에 mapping해주는 것이다.
- 확정적 정책: 테이블 형태로 정해져있는 경우
- 확률적 정책: 확률 분포가 주어져있다.

참고) 정책기반 강화학습 방법론
정책을 학습한다는 것은 확률적 정책을 학습하는 것이고 이게 학습 관접에서 유리하다.
optimal policy
감가율이 반영된 미래 보상합의 최대화하는 정책 최적 정책이라고 한다.
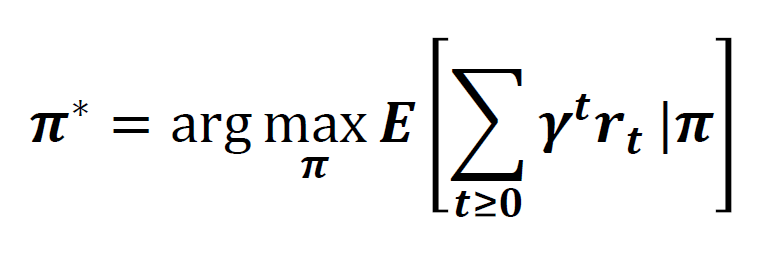
벨만 기대 방정식
결국 가치 함수를 구해야 하고 이를 구하기 위한 방정식이 벨만 기대 방정식이다
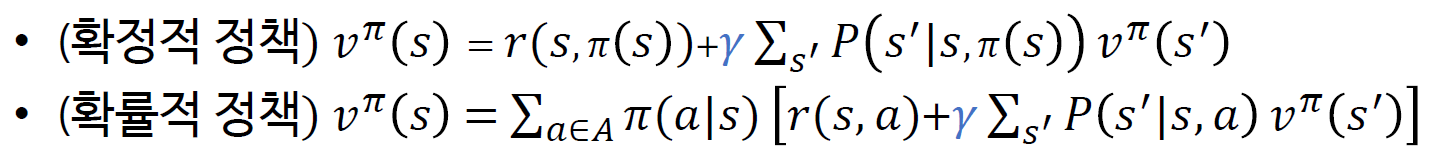
벨만 최적 방정식
앞서 구한 가치함수를 가지고 재귀식 형태로 표현한 것이다. 이 때 좌변과 우변의 가치함수는 같다고 간주한다.
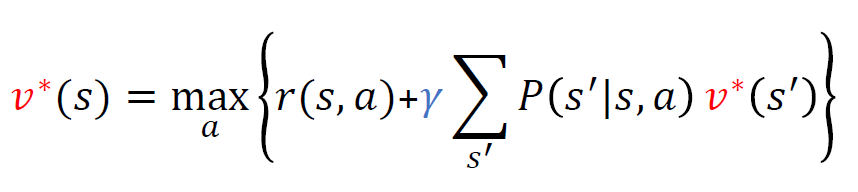
iteration
벨만 기대 방정식에서 좌변과 우변의 가치함수값이 동일하다는 점을 이용해서, 가치함수값을 찾는 방법으로 iterative하게 구하는 방법이 있다.
- 가치 반복
- 정책 반복
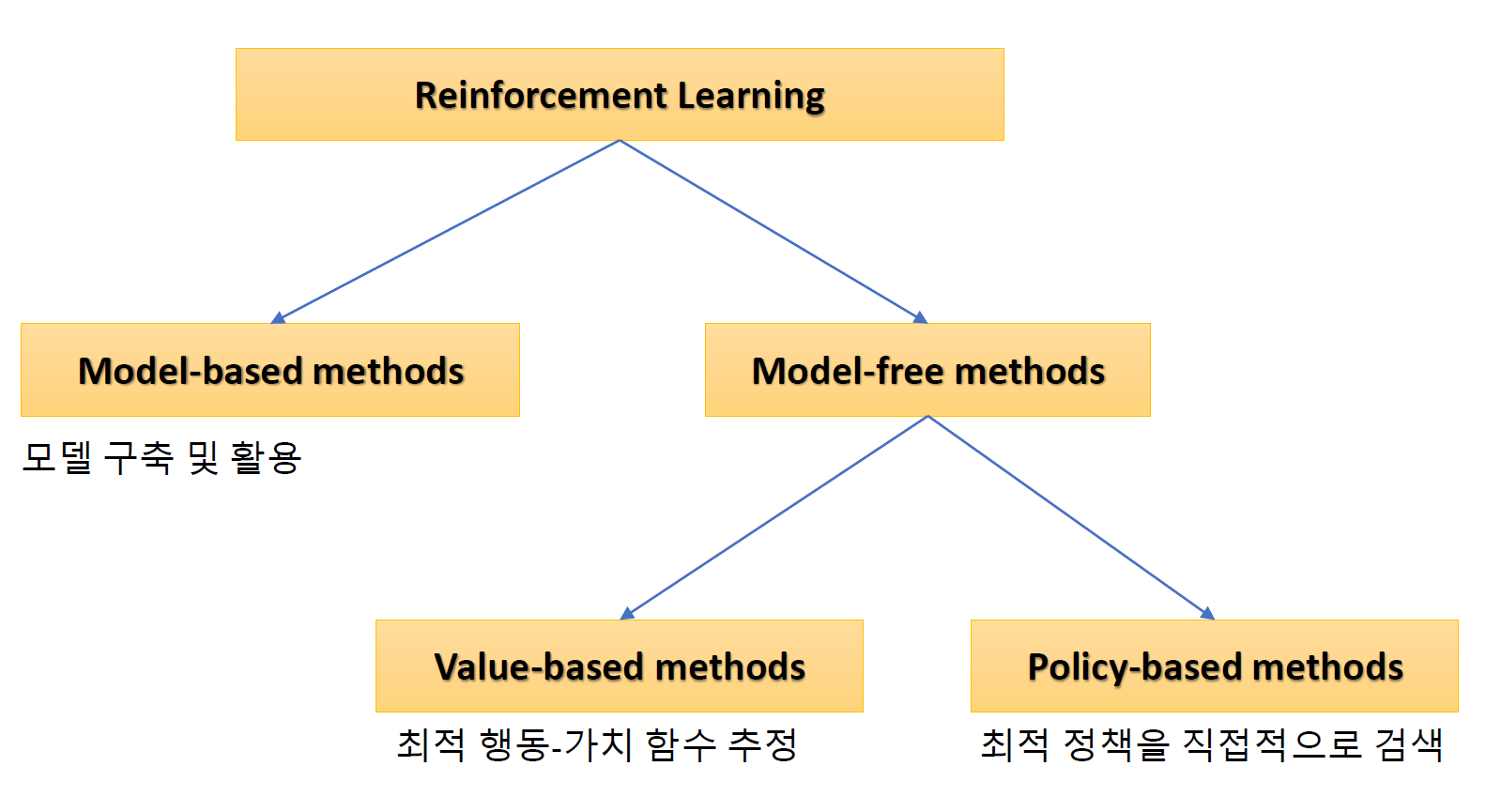
차이점
강화학습은 환경에 대한 가정을 모르는 상태에서 학습하는 것이 가장 큰 차이점이다. 즉, reward, 상태 전이 확률에 대한 정보가 없는 상태에서 학습을 진행하게 된다. 그래서agent가 environment와 상호작용하면서 학습하는 것을 말한다.
- model based method : 환경과 상호작용하고 데이터를 수집하고, 상태전이확률과 보상을 추정하게 된다.
- model free method : 데이터로부터 학습을 진행
- value based method: 최적 행동가치함수 추정
- policy based method : 최적 정책을 직접 검색, 개선하는 방법
모델 기반 강화학습
데이터로 부터 MDP(상태전이확률과 보상)을 추정
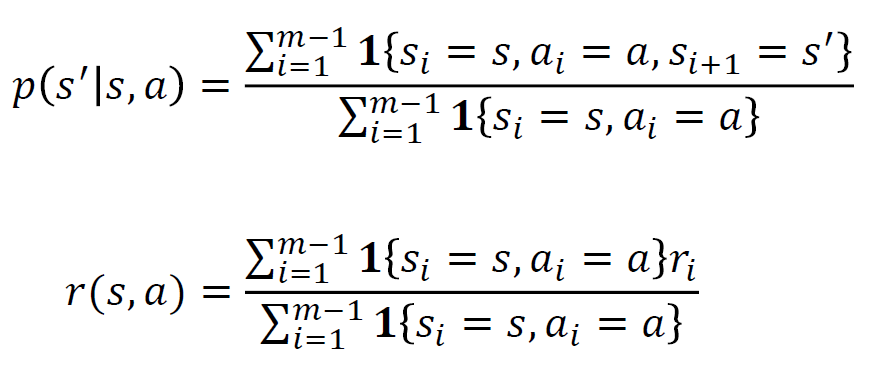
댓글남기기