[KMOOC 강화학습] Week 10-2 SARSA
해당 강의는 K-MOOC의 “강화학습의 수학적 기초와 알고리즘 이해” 수업을 수강하며 기록한 내용입니다. 강의는 링크에서 확인하실 수 있습니다.
Generalized Policy Iteration
정책 평가와 개선 총 2가지 프로세스로 구성되어 있고, action을 수정해나간다.
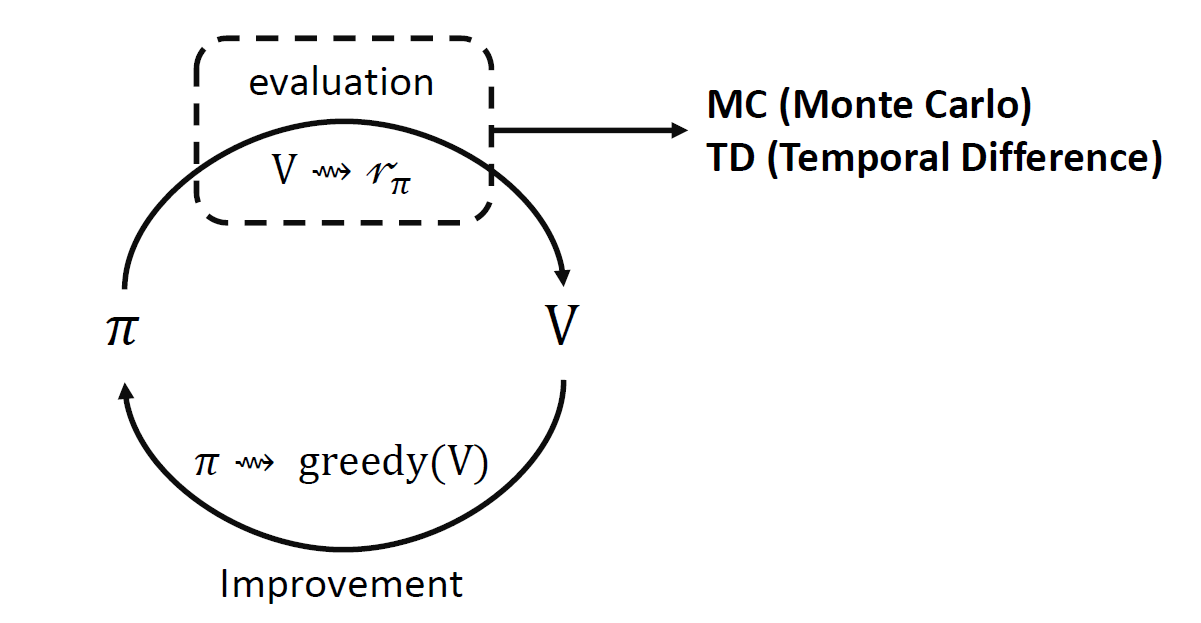
정책 평가하기 위해 가치함수를 계산하던 것이 배운게 MC와 TD 방법이다.
그렇다면 어떻게 개선해나갈까?
SARSA
행동-가치 함수(Q(s,a))를 TD기반으로 학습하는 방법
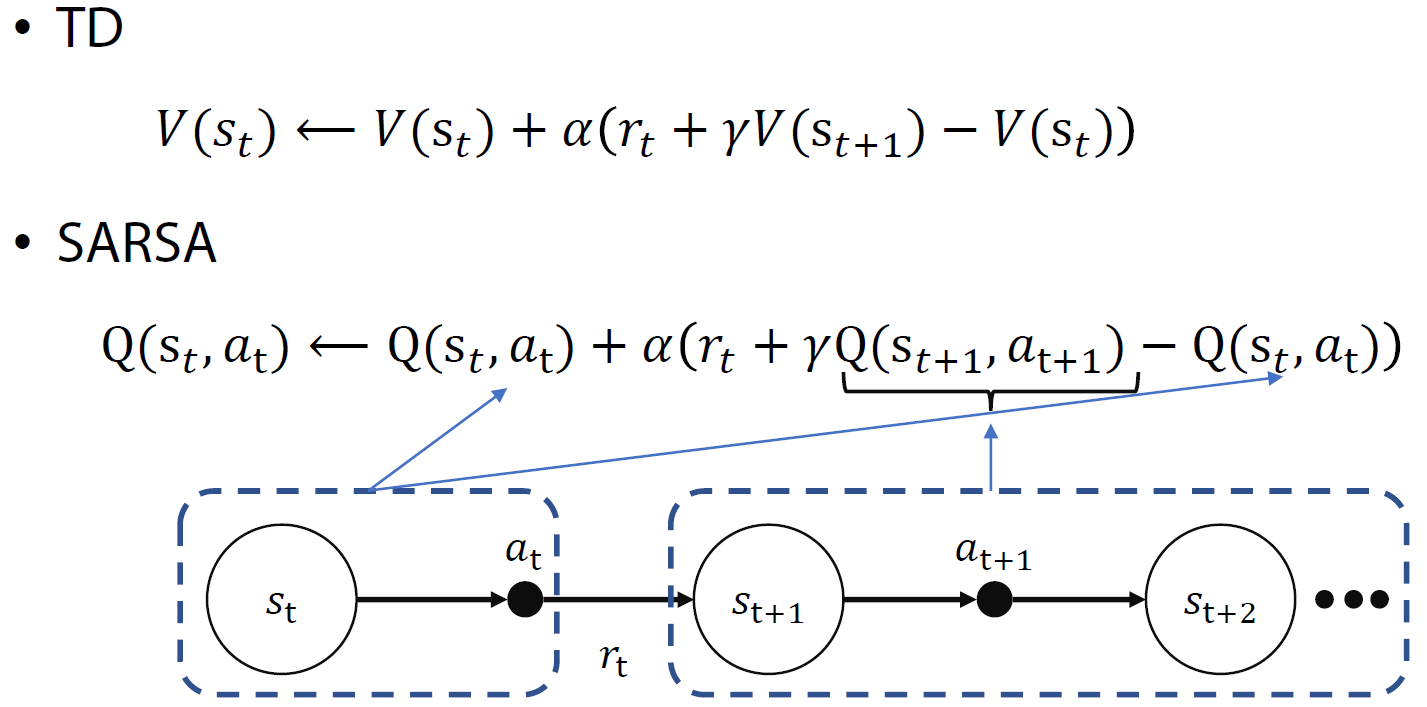
중요한 점은 다음 상태에서의 행동까지 이용하게 되어서 이름도 S-A-R-S-A가 된 것이다.
재귀식
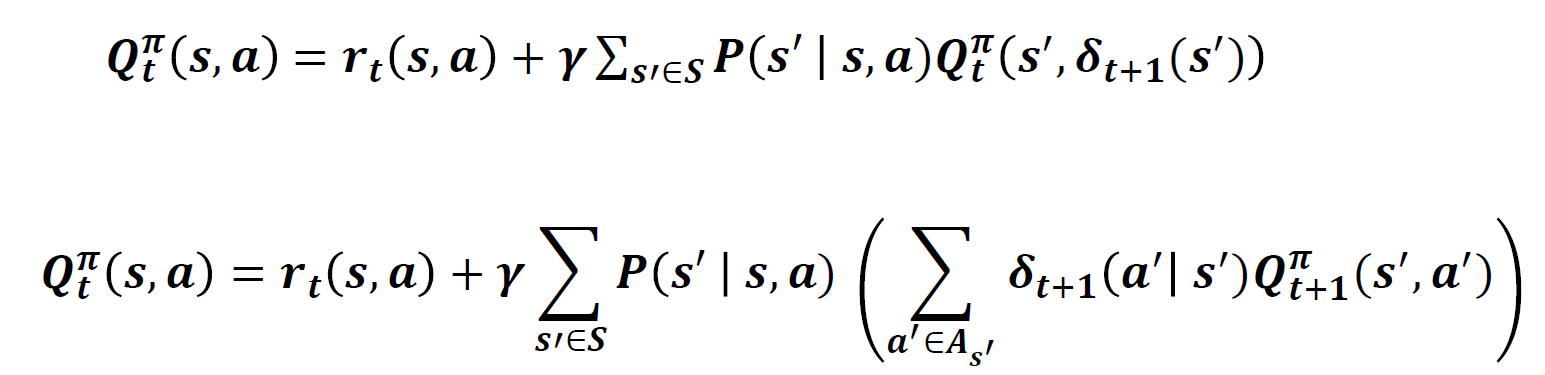
업데이트는 보상은 알고 있고, 상태 전이 확률을 모르는 상태니 임의의 s’이란 상태에서 사전에 알려진 정책에 의해 얻은 $\gamma Q(s_{t+1},a_{t+1})$ 로 계산하게 되는 것이다.
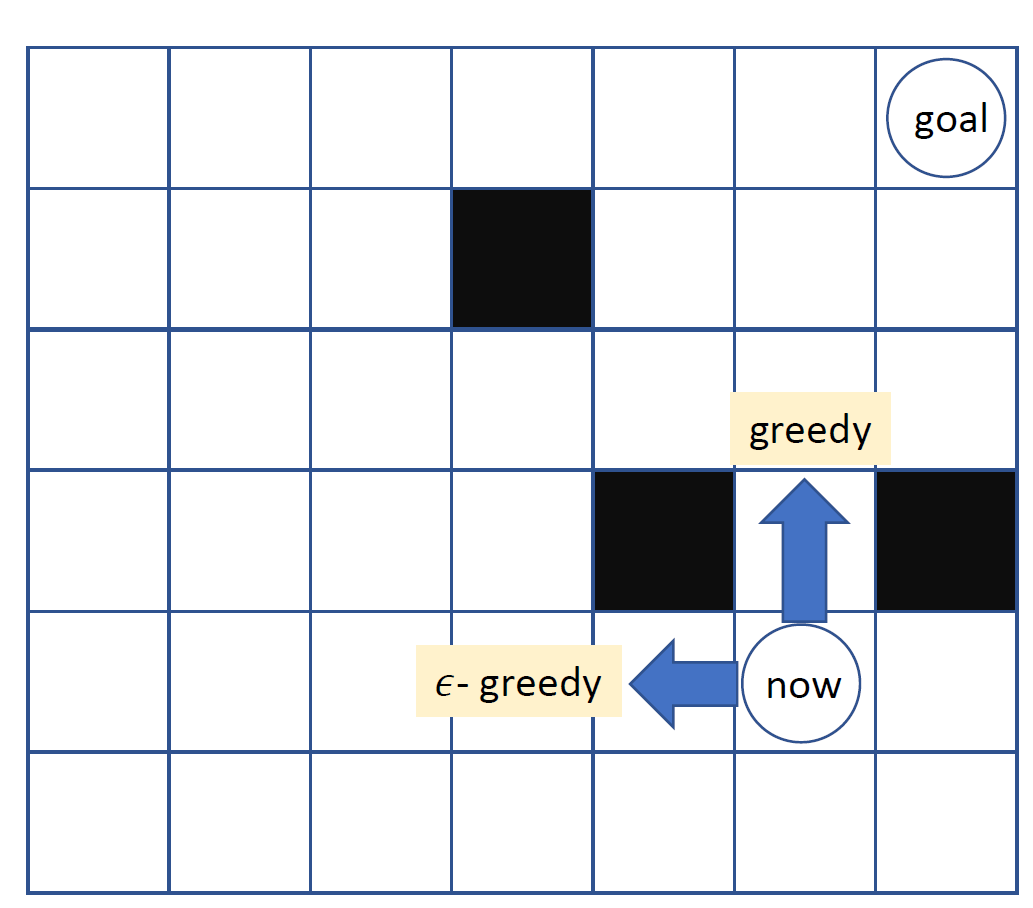
epsilon greedy policy
exploitation과 exploration의 trade off가 중요한데, 짧은 학습으로 배운 것만 사용하게 되면 매우 위험하게 되니 이것저것 다 알아본 exploration이 강화학습에서는 중요하게 된다.
greedy 방식은 현재 상태에서 내가 가진 정보에서 가장 좋은 선택을 하게 된다. 그렇기 때문에 지금 가진 Q함수의 추정치들의 최댓값을 선택하도록 한다. 다만 이런 방식은 충분히 학습도니 경우에만 적절하다. 그렇기 때문에 다른 행동들도 경험해볼 필요가 있다.
그래서 등장한 것이 epsilon greedy 방식이다!
이 방식은 1-eps 확률로 max인 것을 선택하고 eps 확률로는 다른 임의의 행동을 선택하도록 한다.
Update rule
기본적으로 현재 상태에서 행동을 선택하는 정책을 행동 정책이라고 하며 행동 가치 함수를 학습하기 위해 다음 상태 s’에서 취할 행동을 선택하는 정책은 타겟 정책이라고 한다.
필요한 데이터는 총 $[s_{t}, a_{t}, r_{t}, s_{t+1}, a_{t+1}]$ 이다.
이를 구하기 위해 현재 상태가 있고, eps greedy로 행동을 선택하게 되고 다음 상태로 전이한 다음 그 상태에서 다시 esp greedy로 그 다음의 행동을 정하게 되어서 필요한 데이터를 구축하게 된다.
- 모든 행동 가치 함수는 0으로 초기화
- 현재 정책에서 행동 a를 선택하여 보상 r을 얻고 다음상태 s’로 전이한다.
- 현재 정책을 따라 행동 a’를 얻게 된다. 이렇게 하면 Q(s,a)를 얻게 된다.
- Update 식을 이용하여 개선하고, s’은 s로, a’은 a로 변경한 다음에 반복한다.
SARSA에서는 행동정책과 타겟 정책이 같은경우다. 즉 sample을 위한 선택 방법과 정책은 구분되어야 하긴 하다.
Ex
Windy Gridword : TimeStamp-Epsidoe 간 기울기가 증가하는 것은 결국 한 에피소드 해결을 위한 단계가 줄어드는 것을 확인할 수 있다.
MC: 이 방식을 사용하게 되면 종결 상태에 도달하지 못해서 계산하지 못하는 경우도 존재한다.
Expected SARSA
Q함수의 추정치를 구할 때 실현 가능한 행동들에 대해서 행동가치의 기댓값을 이용하게 된다. 즉 다음 단계에서의 행동 가치함수를 계산할 때에 기댓값을 사용하게 되는 것이다!
댓글남기기