[Paper] DGCN
“DGCN: Diversified Recommendation with Graph Convolutional Networks “이란 논문에 대한 리뷰입니다.
원문은 링크에서 확인할 수 있습니다.
1. Introduction
기존의 diversity model의 경우
-
candidates가 생성된 이후에 post-processing 형태로 사용
-
Learning To Rank(LTR)기반의 방법들은 candidates를 생성하지 말고 ordered list를 바로 생성해내는 방법을 제안
-
다만 post-processing이라는 점에서 embedding을 학습시키는 mating process와는 분리된 형태
Graph 관점에선
-
기존엔 random walk 혹은 GCN과 같은 모델을 사용
-
bipartite라는 점에서 한 사용자의 higher order neighbor는 비슷한 사용자가 좋아하는 아이템을 포함한다는 점에서 더 diverse
- GCN의 경우에는 embedding 학습(relevance)와 diversity가 분리된다는 문제를 해결할 수 있습니다.
- 다만 higher order neighbor가 서로 비슷하지 않은 아이템을 말하진 않습니다.
해당 페이퍼에선
-
GCN으로 category diversification을 타겟
-
Negative samppling을 이용하여 비슷하지만 negative한 아이템을 뽑을 확률을 상승
-
궁극적으로 다양성을 반영하는 프로세스가 embedding 학습 과정에 반영되도록 하는 모델을 제안
2. Preliminaries
2.1 Diversity
한 사용자의 추천 목록안에서 아이템들이 서로 얼마나 다양한지
서로 다른 사용자에게 추천되는 아이템들이 얼마나 다양한지
2.2 Recommendation Pipeline

Step 1. Matching : user, item 임베딩으로 interaction probability를 기준으로 전체 아이템 목록에서 추천할 후보들을 정합니다.
Step 2. Scoring : 후보들 중에서 일종의 점수를 매기고 top-k를 선택합니다.
Step 3. Re-ranking : 각각 목적에 따라 top-k를 재배열합니다.
기존의 방식에선 Re-ranking에서 diversity를 반영한 것이라 matching 단계에선 diversity와는 무관했고, 본 논문에선 matching 단계에서 반영되는 방식을 다루는 것입니다.
3. Method
3.1 Overview
-
Rebalanced Neighbor Discovering : 주요 카테고리는 제한적이면서 마이너 카테고리는 올라간 확률로 sampling해서 graph를 구성
-
Category-Boosted Negative sampling : simliar but negative item이 뽑힐 확률를 올려서 비슷한 아이템들 중에서 사용자의 선호도를 학습
-
Adversarial Learning : 카테고리 분류를 adversarial learning으로 학습시켜서 사용자의 item에 대한 선호도를 이용해 카테고리에 대한 선호도를 알아내어 category에 대한 데이터 없이 임베딩을 학습
3.2 GCN
3.2.1 임베딩 환경
$M$ : the number of users
$N$ : the number of items
$d$ : the dimension of embedding
3.2.2 Convolutional Layer
$kth$ layer의 node $v$의 계산과정은 다음과 같습니다.
$h_{AGG}^{k} = MEAN(h_{j}^{k-1}, \forall j \in \mathcal{N}(v))$
$h_{v}^{k} = \tanh (W^{k}h^{k}_{AGG})$
- $\mathcal{N}(v)$ 는 sampled neighbor set이며 self node도 포함되어 있습니다.
3.2.3 Interaction Modeling in matching stage
gonvolutional layer의 마지막 representation의 내적으로 interaction probability를 계산합니다.
$\mathcal{p}(u,i)$ = <$h_{u}^{K}, h_{i}^{K}$>
3.3 Rebalanced Neighbor Discovering
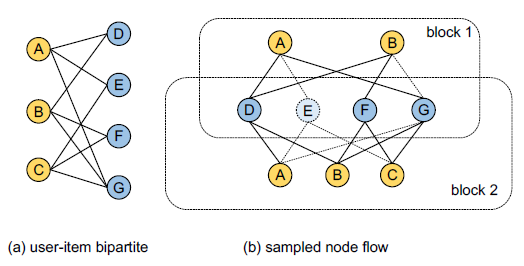
item 수가 매우 크기 때문에 neighbor sampler가 사용하는데 이 neighbor sampler는 일종의 Node Flow처럼 작동합니다.
이는 첫 layer에선 ranodm하게 neighbor를 샘플링하고 다음 레이어에서는 직전 레이어를 바탕으로 neighbor를 샘플링하게 됩니다.
즉 하나의 convolutional layer에서는 하나의 sub graph(block)을 연산에 사용하게 됩니다.
diverse한 목록이라는 것은 한 사용자에게 자주 보는 카테고리(dominant)와 그렇지 않은 카테고리(disadvantaged)는 구분해서 dominant와 disadvantaged 카테고리 모두 추천할 수 있어야 합니다.
그래서 해당 논문에선 disadvantaged 카테고리를 샘플링할 확률을 올려주고 dominant는 줄여주는 것입니다.
사용자 node에 대해선
- 연결된 아이템($i$)마다 카테고리($\mathcal{C}(i)$)의 히스토그램($H(\mathcal{C}(i))$)을 계산합니다.
- (${1 \over H(\mathcal{C}(i))}^{\alpha}$)을 샘플링 확률로 사용하고 이때 $\alpha$를 rebalance weight라고 부릅니다.
아이템 node에 대해선
- 연결된 사용자를 uniform sampling으로 진행합니다.
이렇게 진행하면 사용자 임베딩에 보다 다양한 카테고리 정보가 반영되고, 추천할 때엔 이렇게 학습된 사용자 임베딩으로 최종 추천 목록을 만들게 됩니다.
한 레이어의 block을 구성하는 알고리즘은 다음과 같습니다.
- 각 node마다 샘플링 확률을 구합니다.
- 사용자 node는 히스토그램의 power inverse를, 아이템 node는 uniform 분포값을 가져옵니다.
- 각 node 마다 다음 샘플을 모으게 됩니다.
- 이를 원하는 GCN $depth K$만큼 진행합니다.
3.4 Category-based Negative Sampling
기존에 implicit feedback을 사용할 경우 positive sample은 다루지만 negative sample은 기록이 없는 아이템에서 생각해야한다는 단점이 있습니다.
그래서 negative sample을 postive sample마다 적절한 수만큼 뽑아서 사용자 임베딩은 positive sample과는 비슷해지게, negative sample과는 달라지게 학습했었습니다.
해당 논문에서는 similar but negative 아이템을 서용한다고 합니다.
simlar but negative란 positive sampler과 같은 카테고리 내 item을 말합니다.
즉 positive category에서 negative sample을 뽑아서 같은 카테고리이지만 negative sample은 최종 추천단계에서 덜 뽑히게 되어 다양하게 만드는 방식입니다.
알고리즘은 다음과 같습니다.
- 각 positive sample $i$를 준비합니다.
- 전체 아이템 집합에서 $i$를 제외한 집합 N, 같은 카테고리 아이템 집합에서 $i$를 제외한 집합 S를 준비합니다.
- $\beta$에 따라 S나 N 중에서 하나를 선택하여 샘플링 한 것을 negative sample로 사용합니다.
- $\beta$는 사전에 정한 simliar but negative 비율을 말합니다.
- 이를 negative sample rate $T$만큼 반복합니다.
- 최종적으로 모든 positive sample과 Step 3의 샘플링으로 뽑은 negative sample을 최종 training에 사용하는 데이터 셋이 됩니다.
$\beta$값이 증가할수록 positive category에 속하지만 negative하다고 정해진 item이 늘어나 결과적으로 negative 카테고리 중 positive 아이템이 추천될 확률이 증가하는 방식으로 작동하게 됩니다.
| 전체 training sample의 구성 변화 | ||
|---|---|---|
| $\beta \uparrow$ | positive(dominant) category | negative(disadvantaged) category |
| positive item | 고정(positive sample) | 감소(negative sample) |
| negative item | 증가(negative sample) | 감소(negative sample) |
| 최종 추천될 확률 변화 | ||
|---|---|---|
| $\beta \uparrow$ | positive(dominant) category | negative(disadvantaged) category |
| positive item | $\cdot$ | 증가 |
| negative item | 감소 | $\cdot$ |
3.5 Adversarial Learning
adversarial learning 방식을 위해 별도의 카테고리 classifier도 학습해서 diversity를 올리고자 합니다.
카테고리 classifier의 obejctive과 같습니다.
$\hat{c} = Wh_{i}^{K}$
$\min L_{c}(i,c) = -\hat{c}[c] + \log (\sum_{j} \exp (\hat{c}[j])) $
추천에 대한 objective는 다음과 같습니다.
$y$는 user-item간 연결 여부
$c$는 아이템의 카테고리
$h^{K}$는 GCN의 최종 embedding
$\hat{y}$=<$h_{u}^{K},h_{i}^{K}$>
$L_{r} (u,i,y) = -[y*\log \sigma (\hat{y})+ (1-y)\times \log \sigma(1-\hat{y})]$
$\min (L_{r} - \gamma L_{c})$
이렇게 진행할 경우 classifier의 업데이트 과정에서 비슷한 카테고리의 item들의 임베딩을 달라지도록 진행되어 같은 카테고리끼리 뭉치지 않게 진행합니다.
동시에 $L_{r}$을 통해 사용자의 아이템에 대한 선호도를 적절히 학습하도록 합니다.
이러한 학습 과정은 실제 적용을 위해 Gradient Reversal Layer(GRL)을 classifier에 input되기 전에 거치도록 진행합니다.
이렇게 한다면 GCN에 영향끼치는 classifier의 gradient가 뒤집혀지게 됩니다.
we perform gradient descent on the parameters of the classifier, hile perform gradient ascent on the parameters of GCN, with respect to $L_{c}$
Experiments
시간 순서대로 앞의 60%의 데이터를 train set으로 사용하고 그 다음 20%는 validation & tuning으로 마지막 20%는 test set으로 사용합니다.
Interaction probability를 내적으로 사용하기 때문에
user vector를 일종의 query vector로 사용하고 내적을 기준으로 가장 가까운 neighbor를 찾는 방식으로 추천 목록을 구성합니다.(Faiss와 IndexFlatIP라는 방식)
결과를 정리하면 다음과 같습니다.
- benchmark들 모두 relevance, diversity trade-off는 확인되었습니다.
- DPP와 비교했을 때 두 지표 모두 성능이 좋고 특히 diversity가 올라감에 따라 accuracy가 감소하는 정도가 DGCN이 더 작았습니다.
- classifier의 성능은 adversarial learning이 없었을 때 증가하고 diversity는 감소하는 것으로 통해 adversarial learning이 같은 카테고리 아이템끼리 뭉치지 않게 하는 효과가 있음을 확인
- $\alpha$가 증가하면서 disadvantaged category에 더 높은 샘플링 확률이 부여되어 rebalance 효과가 증가하였고 accuracy또한 어느 정도 증가 이후 감소했다는 특징 확인
- $\beta$가 증가할 수록 diversity와 accuracy간 trade off 확인
댓글남기기