[Paper] PD-GAN
“PD-GAN: Adversarial Learning for Personalizaed Diversity-Promoting Recommendation”이란 논문에 대한 리뷰입니다.
원문은 링크에서 확인할 수 있습니다.
1. Introduction
Trade-off between relevance and diversity of recommendation lists
아이템 리스트의 diversity를 높이다 보면 relevance가 낮아지는 문제가 생기게 되고,
이를 해결하려는 것이 personalized diversity promoting recommendation model .
본 모델에서 다루는 personal preference는 2가지로 다음과 같습니다.
- personal preference to individual items
- ground truth에 속한 각 아이템들의 역할
- personal preference to the diversity of a set of items
- ground truthd 집합 자체의 역할
본 모델은 GAN framework를 사용하여 Personalizaed Diversity-promoting GAN이라고 불리고
특히 GAN의 generator는 DPP model을 바탕으로 구성되며 특징은 다음과 같습니다.
- Personalized -> 각 유저마다 DPP kernel matrix를 구성
- user’s preferenence to item -> 아이템과의 relevance를 학습
- co-occurence of items -> 아이템의 diversity를 학습
3. PD-GAN Model
데이터 셋 구성
$M$명의 user와 $N$개의 item 그리고 $C$개의 item category로 구성을 하고,
각 아이템은 최소한 하나의 item category를 가지게 됩니다.
각 유저 $u$ 마다 random sampling한 observed diverse set $T = \lbrace i_{1}, …\rbrace$ 를 만드는데
이 때 각각의 아이템은 서로 다른 category들을 가지게 됩니다.
다양한 아이템을 본 사용자(eclectic)의 T의 cardinality는 커지게 되고 일부 아이템만 본 사용자(focused)의 T의 cardinality는 작을 수 밖에 없습니다.
The cardinality of T will naturally be larger for eclectic users than that for focused users.
이와 같은 방식으로 각 사용자마다 여러개의 diverse set을 만들 수 있고 다음과 같이 표기하며 ground truth로 사용하게 됩니다.
$\mathcal{T}(u) = \lbrace T_{1}, T_{2}, … \rbrace $
이렇게 구성하였을 때
- 각각의 아이템들은 observed data에서 뽑았으니 해당 사용자의 특정 아이템에 대한 선호도 정보를 가지고 있으며,
- 각각의 아이템 셋은 data의 category 구성에 따라 뽑았으니 해당 사용자의 diversity에 대한 선호도 정보를 가지고 있다고 합니다.
그 결과 ground truth와 유사하게 diverse하고 relevant한 추천을 진행하는 것이 바로 모델의 개념적인 원리입니다.
모델 구조
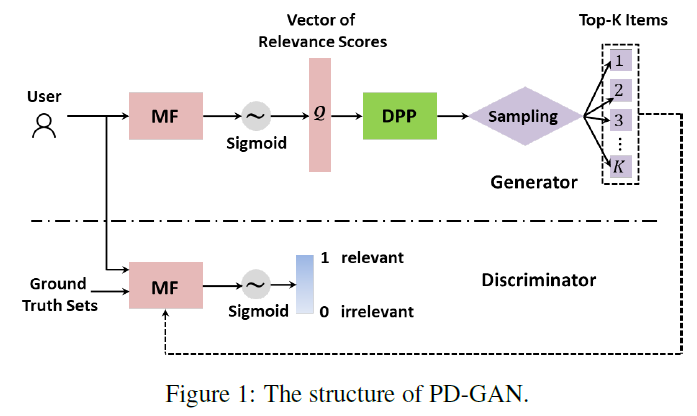
- 각 사용자마다 generator는 모든 아이템을 대상으로 Maxtrix Factorization(MF)를 통해 relevance를 평가합니다.
- diverse item의 co-occurence를 학습하는 pre-learnt DPP를 준비합니다.
- relevance 평가 결과와 pre-learnt DPP를 합친 modefied DPP 모델에서 순차적으로 top-K item을 sampling
- 이것이 Generator의 output이 됩니다.
- Discriminator는 Generaot가 만든 top-k item과 grount truth를 구분하도록 학습합니다.
The generator will be able to generate a set of diverse and relevant items so similar to the ground-truth that discriminator will not be able to distinguish easily
ground truth와 유사한 아이템 셋을 뱉어 내는 것이니 앞서 diversity는 아이템 셋으로 학습한다는 것이 것이 말이 된다고 생각합니다.
Generator - Relevance
이 때 MF를 이용하여 quality evaluating function을 정의하면 다음과 같습니다.
- $\mathcal{Q} (u,i) = \sigma (v_{\mathcal{G}}^{u}*v_{\mathcal{G}}^{i})$
- $v_{u}, v_{i}$ 는 $1\times D$ embedding vector이며 $\sigma$는 sigmoid function을 말합니다.
Generator - Diversity
discreset set $\mathcal{L}$에 subset T에 대해서 pre-learnt DPP는 다음과 같이 정의됩니다.
$\mathcal{P}(T) \propto \det(L_{T})$
$\mathcal{P}(T) = {\det(L_{T}) \over \det(L+I)}$
L-ensemble을 사용한다고 할 때 N이 커질 수록 계산 복잡도가 매우 커지므로 Low rank factorization을 진행하게 됩니다.
$L =AA^{T}$ where A is $N \times D $
L-ensemble을 학습하는 과정은 다음과 같습니다.
- 전체 사용자들의 ground truth에서 몇개의 diverse set을 sampling하게 됩니다 .
- $\mathcal{T} = \cup_{u=1}^{M} \mathcal{T} (u) =\lbrace T_{1}, T_{2}, … T_{X}\rbrace$
- Gradient decent방식으로 $\log \mathcal{P}(\mathcal{T}\mid A)$을 maximizing하여 L을 학습합니다.
이 방식을 통해 diverse item 중에서 더 많이 함께 뽑힐수록 더 높은 확률을 가지도록 학습하게 됩니다.
다만 이 방식의 문제점은 많은 사람들이 본 아이템은 많이 뽑힌다는 문제가 존재해서 다음과 같은 방식으로 학습을 하게 됩니다.
- 앞서 뽑은 diverse set마다 동일한 카테고리를 가지는 아이템으로 구성된 similary set $\tilde{T}$를 만듭니다.
- $< \mathcal{T},\tilde{T} > = \lbrace < T_{1},\tilde{T_{1}} >,… < T_{X},\tilde{T}_{X} > \rbrace$
- 다음 objective를 최적화 한다면 두번째 항을 통해서 유사한 아이템이 등장할 확률을 줄일 수 있습니다.
- $ \max \mathcal{J} = \log \mathcal{P}(\mathcal{T}\mid A) - \log \mathcal{P}(\tilde{T}\mid A) $
- $\max \mathcal{J} = \sum_{x=1}^{X} \log \mathcal{P} (\mathcal{T_{x}} \mid A) - \log \mathcal{P} (\tilde{T_{x}} \mid A) $
- $\max \mathcal{J} = \sum_{x=1}^{X} \log \det(L_{[T_{X}]}) - \log \det(L_{[\tilde{T}_{X}]})$
Generator - Modified DPP
pre-learnt DPP과 달리 Relevance를 합친 modified DPP는 다음과 같은 특징이 있습니다.
$\mathcal{P}(T) \propto \alpha \sum_{i\in T}\mathcal{Q}(u,i) + (1-\alpha) \det(L_{T}) = \det(L_{u}) $
- $\mathcal{Q}(u,i)$는 quality-evaluating function으로 사용자마다 아이템과의 relevance를 나타내는 함수이며 $\alpha$는 relevance와 diversity를 조정하는 hyperparameter로 사용됩니다.
그 결과 각 사용자마다 modified DPP의 kernel은 다음과 같이 정의됩니다.
- 각 아이템들에 대해서 quality evaluating function을 구해서 하나의 벡터로 만들고 이를 $\mathcal{Q}(u)$라고 합니다.
- $L_{u} = Diag(\exp (\beta \mathcal{Q} (u))) * L * Diag(\exp (\beta \mathcal{Q} (u))) $
- $\beta = {\alpha\over 2(1-\alpha)}$
Generator - Sampling
최종적으로 modified DPP를 순차적으로 top-K개의 아이템을 sampling을 진행하게 되는데 본 논문에서는 fast greedy MAP inference를 이용하여 그 결과를 $T_{\mathcal{G}}$라고 합니다.
Discriminator $\mathcal{D_{\eta}}(u,T_{\mathcal{G}})$
각 사용자마다 Generator가 생성한 $T_{\mathcal{G}}$의 relevance를 평가하는 것이 discriminator의 역할입니다.
output은 [0,1]이며
값이 클수록 Generator가 생성한 아이템들이 relevance가 높다고 알려주는 일종의 score를 의미합니다.
logistic MF를 사용하며 정의는 다음과 같습니다.
$\mathcal{D_{\eta}} (u,T_{\mathcal{G}}) = \sigma({1\over \mid T_{\mathcal{G}} \mid}\sum_{i\in T_{\mathcal{G}}}v_{\mathcal{D}}^{u} \times v_{\mathcal{D}}^{i})$
- 중요한 점은, Generator에서도, Discriminator에서도 MF를 사용하기 때문에 각각 MF를 위해 사용하는 embedding vector는 구분되어야 합니다.
Optimization
Generator의 objective
$\min_{\theta} \sum_{u=1}^{M} \log (1-\mathcal{D}(u,\mathcal{G_{\theta}}))$
중요한 점은, sampling이 순차적으로 진행되기 때문에 강화학습 방식을 사용해서 진행해야 하며
Generator의 objective를 수정하면 다음과 같습니다.
$ \max_{\theta} \mathcal{J}(T_{\mathcal{G}}) = \sum_{i=1}^{K} \mathcal{R}(u,T_{\mathcal{G}}) \log \mathcal{Q}(u, i)$
- $\mathcal{Q}(u, i)$는 posterior probability 역할을 합니다.
- reward function $\mathcal{R}(u,T_{\mathcal{G}}) = -\log (1-\mathcal{D}(u,T_{\mathcal{G}}))$
- 이렇게 정의할 경우 discriminator가 판단하기를, Generator가 생성한 아이템의 relevance score가 높다고 한다면 Generator는 잘 생성하고 있기 때문에 reward는 더 증가하게 되는 구조입니다.
Discriminator의 objective
$\max \mathcal{J_{\mathcal{D}}} = {1\over \mid \mathcal{T_{u}}\mid} \sum_{T \in \mathcal{T_{u}}} \log \mathcal{D_{\eta}}(u,T) + \log (1-\mathcal{D_{\eta}}(u,T_{\mathcal{G}}))$
Advarsarial Training Process
학습 과정은 다음과 같습니다.
- Pre-train DPP를 학습시킵니다.
- 사용자마다 personalized DPP kernel $L_{u}$를 만들고, top-k를 추출하고, Generator를 학습 시킵니다.
- 해당 단계에서 discriminator는 고정시킵니다.
- 동일하게 top-k를 추출하고, Discriminator를 학습시킵니다.
- 해당 단계에서 generator는 고정시킵니다.
- Step 2와 Step 3를 수렴할 때까지 학습합니다.
4. Experiment
Model Training
Dataset
Movielens(100K)
- 100K ratings of 1 to 5
- 18 categories
Anime
- 1 million ratings of 1 to 10
- 44 categories
Dataset 처리
- Movielens와 Anime을 각각 5점과 10점을 positive feedback으로, 그 외 점수들은 unknown feedback으로 처리
- 특히 Anime에선 또한 rating수가 300개 이하인 아이템과 사용자 정보는 사용
- ground truth diverse sets은 positive feedback에서 sampling하며 새로운 카테고리인 경우에만 추가하도록 구성
- similar set은 동일한 카테고리이면서 positive feedback인 데이터를 사용
실험결과 특징
Trade-off
- Relevance를 평가하는 metric인 Precision과 diversity를 평가하는 metric인 Category coverage는 $\alpha$값 변화에 따라 trade-off 관계가 확인되어 적절히 작동하는 것으로 판단됩니다.
- 다만 PD-GAN의 경우에는 두 metric을 어느정도 커버하는 결과가 확인되었습니다.
Advarsarial Training
- diversity는 epoch이 진행하면서 꾸준히 증가하는 반면 relevance는 증가한 이후 감소하는 형태가 확인됩니다.
- 이는 Generator가 ground truth와 비슷해지도록 학습해 성능이 같이 증가한 것이며 relevance는 어느정도 상한선이 있는 것으로 확인됩니다.
생각하는 한계
- ground truth 구성방법에 따라 성능의 변화가 클 것으로 생각
- 앞서 말한 것 다양한 아이템을 본 사람과 특정 아이템만 본 사람들의 ground truth의 cardinality가 차이가 있다는 점에서 다양한 것을 보지 않은 사람에게 다양성을 추구하는 방향의 학습이 부족하다고 생각합니다.
댓글남기기